This is Part 2 of a discussion of how sourcing talent or outcomes in the tails or extremes of a distribution call for our selection criteria to embrace more variance than searches in the heart of a distribution. To catch up please read There’s Gold In Them Thar Tails: Part 1.
If you can’t be bothered here’s the gist:
- We saw that an explosion of choice whether it’s a job or college applicants, songs to listen to, athletes to recruit has made selection increasingly difficult.
- A natural response is to narrow the field by filtering more narrowly. We can do this by making selection criteria stricter or deploying smarter algorithms and recommendation engines.
- This leads to increased reliance on legible measurements for filtering.
- Goodhart’s law expects that the measures themselves will become the target, increasing the pressure on candidates to optimize for narrow targets that are imperfect proxies or predictors of what the measure was filtering for.
- Anytime we filter, we face a trade-off between signal (“My criteria is finding great candidates”) and diversity. This is also known as the bias-variance trade-off.
- Diversity is an essential input to progress. Nature’s underlying algorithm of evolution penalizes in-breeding.
- In addition to a loss of diversity, signal decays as you get closer to the extremes. This is known as tail divergence. The signal can even flip (ie Berkson’s Paradox).
- The point where the signal noise overwhelms the variance in the candidates is an efficient cutoff. Beyond that threshold, selectors should think more creatively than “just raise the bar”.
At the end of part 1, there were strategies for both the selector and the selectees to increase diversity to improve outcomes in the extremes.
If narrower filters are less effective in the tails (ie more noise, weaker correlations between criteria and match quality), we should be intentional about the randomness we introduce to the process. A 1500 SAT is a noisy predictor of “largest alumni donor 20 years from now”. Instead, accept the 1350 SAT from the homeschooled kid in Argentina. Experiment with criteria and let chance retroactively hint at divergent indicators that you would never have thought to test. One of the benefits of such an experiment is that if you are methodical about how you introduce chance you can study the results for a hidden edge. If nobody else has internalized this thinking because they think it’s too risky (it’s not…the signal of the tighter filter had already degraded), then you have an opportunity to leap ahead of your competitors who underestimate the optionality in trying many recipes and keeping the ones that taste good. You tolerate some mayonnaise liver sandwiches before you discover pb&j.
In part 2, we reflect on what tail divergence says about life and investing.
Where Instincts Fail
Tail divergence is the simple observation that attributes that correlate with certain outcomes lose their predictive ability as we get into the extremes. If you are 6’7, you’re better at basketball than most of the population. But you couldn’t step foot on the hardwood with the lowly Rocket’s 12th man. Taken further, Berkson’s Paradox shows that it’s possible for the correlation to flip. LessWrong thinks the flippening may be causal because of too much of a good thing:
Maybe being taller at basketball is good up to a point, but being really tall leads to greater costs in terms of things like agility… Maybe a high IQ is good for earning money, but a stratospherically high IQ has an increased risk of productivity-reducing mental illness. Or something along those lines.
The safest generalization to absorb:
When speculating about the tails of a distribution your intuition is less reliable.
If you can pinpoint causality, that’s a bonus. Simply realizing your guesses about extremes is random is an advantage. It splits your brain wide open to get your imagination oxygen.
Behavioral psychology recognizes the usefulness of heuristics to make judgements while highlighting how “biases” such as framing can short-circuit our “System 1” machinery. Intuition is a useful guide when we have deep experience in a domain, but we should seek external data (base rates) or guidance when we stray from the mundane.
If our intellectual adventures take us from “mediocrastian” to “extremistan” then data is not necessarily a helpful tour guide. It can even be harmful if it encourages a false sense of security or a load-bearing assumption that turns out to be hollow .
A recent example of intuition failing in an extreme scenario still stings. When Covid first started spreading in the US, asset prices and city rents dove lower. Financial markets stabilized and began recovering when the government commit to replacing lost demand with an unprecedented fiscal package for an unprecedented event. My suburban house shot up 15% in value as locked-down city dwellers wanted more space. Seeing the divergence between home price and rentals, I quickly diagnosed the home price bump as a premium needed to absorb a sudden, but transitory urban exodus until we could get a vaccine. While it wasn’t the main consideration for selling the “trade setup” was not lost on me. My intuition in this extreme scenario couldn’t have fathomed that the price would shoot 20% more (and still going, ughh) through where I sold as the lockdowns lifted. My trading intuition degrades less gracefully than I’d like to admit as the orbits get further from financial options.
Moral Intuition
As technology and science fiction converge, it would be dangerous to lazily extrapolate how we handle routine computer-enabled behavior to edge cases. If you have ever played dark forms of “would you rather?” then you are already familiar with the so-called trolley problem:

credit: abpradio.com
The Conversation explains the so-called trolley problem in the context of self-driving cars:
The car approaches a traffic light, but suddenly the brakes fail and the computer has to make a split-second decision. It can swerve into a nearby pole and kill the passenger, or keep going and kill the pedestrian ahead.
This is spiky terrain. What is the value of a life? This is not a novel dilemma. In Tails Explained, I show how courts use probabilities of accidental (ie rare) deaths to estimate tort damages. What is novel is the scale of these considerations once robots take the wheel. The giant fields of AI safety and ethics are proof that scaling up tort law is not going to cut it. We are forced to explicitly study realms that ancient moralities only needed to consider rhetorically.
In Spot The Outlier, Rohit writes:
the systems we’d developed to intuit our way through our lives have difficulty with contrived examples of various trolley problems, but that’s mainly because our intuitions work in the 80% of cases where the world is similar to what we’ve seen before, and if the thought experiment is wildly different (e.g., Nozick’s pleasure machine) our intuitions are no longer a reliable guide.
In The Tails Coming Apart As A Metaphor For Life, Slatestarcodex says:
This is why I feel like figuring out a morality that can survive transhuman scenarios is harder than just finding the Real Moral System That We Actually Use. There’s a potentially impossible conceptual problem here, of figuring out what to do with the fact that any moral rule followed to infinity will diverge from large parts of what we mean by morality.
A wave of exponential automation threatens to capsize our moral rafts. Slatestar invokes one of my favorite paragraphs of all-time to make his point.
When Lovecraft wrote that “we live on a placid island of ignorance in the midst of black seas of infinity, and it was not meant that we should voyage far”, I interpret him as talking about the region from Balboa Park to West Oakland on the map above [This is a metaphor for moral territory he builds in the full post].
Go outside of it and your concepts break down and you don’t know what to do.
The full opening paragraph of Call Of Chtulu deserves your eyes:
The most merciful thing in the world, I think, is the inability of the human mind to correlate all its contents. We live on a placid island of ignorance in the midst of black seas of infinity, and it was not meant that we should voyage far. The sciences, each straining in its own direction, have hitherto harmed us little; but some day the piecing together of dissociated knowledge will open up such terrifying vistas of reality, and of our frightful position therein, that we shall either go mad from the revelation or flee from the deadly light into the peace and safety of a new dark age.
Slatestar edits Lovecraft:
The most merciful thing in the world is how so far we have managed to stay in the area where the human mind can correlate its contents.
This is not an optimistic outlook for our ability to reconcile our based local morality with a species-level perspective. Reasoning about extremes is more futile than we’d like to think. As we search for outliers, we need humility.
Even The Math Prescribes Humility
Let’s translate tail divergence to math terms. We discussed how SAT has predictive power of GPA. The issue is that this power loses efficacy as we get to the top-tier of GPAs, just as being tall starts to tell us less about the best basketball players once we are dealing with the sample that has made it to the NBA.
This loss of signal manifests as a correlation breakdown over some range of the X or explanatory variable. This is the result of the error terms or variance in a regression increasing or decreasing over some range. The fancy word for this is “heteroscedasticity”.
See this made-up example from 365DataScience:

The variance of the errors visibly changes as we move from small values of X to large values.
It starts close to the regression line and goes further away. This would imply that, for smaller values of the independent and dependent variables, we would have a better prediction than for bigger values. And as you might have guessed, we really don’t like this uncertainty.
Ordinary least squares (ie OLS) regression is a common technique for computing a correlation. However, equal variance (homoscedasticity) is one of the 5 assumptions embedded in OLS. Tail divergence is evidence that the data set violates this assumption, so we shouldn’t be surprised when the filters we used in the meat of the distributions lose efficacy in the extremes.
If you broke the regression into 2 separate lines, one for the low to middle range of SAT scores and one for the top decile of SAT scores we could compute different correlations to GPA. If the tails diverge, we would see a lower correlation for the higher range. Correlations even as high as 80% have discouraging amounts of explanatory power.

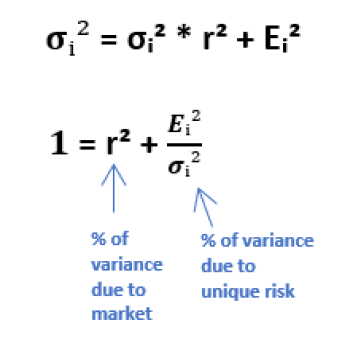
For the derivation, see From CAPM To Hedging.
We shouldn’t be surprised when the most successful person from your 8th grade class, wasn’t a candidate for the “most likely to succeed” ribbon. The qualities that informed that vote leave a lot of “risk remaining” when trying to predict the top performers in the wide-open game of life.
Since the nature of extremes are untamed, we need humility. This is true, but abstract. What does “humility” mean practically? It means making decisions that are robust to the lack of determinism in the tails. In fact, we can construct approaches that actively seek to harness the variance in the tails.
The world of trading and investing is a perfect sandbox to explore such approaches.
Take Advantage of Poor Tail Intuition In Investing
I know the heading is ironic.

Let’s see if we can use “option-like” approaches to use the divergence or uncertainty in the tails to our advantage.
Respect Path
Rohit summarized the argument succinctly:
If measurement is too strict, we lose out on variance.
If we lose out on variance, we miss out on what actually impacts outcomes.
Tails are unpredictable by the same models that might be well-suited for routine scenarios. In fact, rare outcomes can be stubbornly resistant to description by any models in a complex system. The robust response to this situation is not to lean into our models but to relax the filters in favor of diversity, which increases our chance of capturing an outcome nobody has foreseen, because, by definition, nobody’s model could have predicted (and therefore bid it up) in the first place.
How do you do that?
2 words: Respect. Path.
Recall from part 1, that David Epstein’s research-based suggestion:
One practice we’ve often come back to: not forcing selection earlier than necessary. People develop at different speeds, so keep the participation funnel wide, with as many access points as possible, for as long as possible. I think that’s a pretty good principle in general, not just for sports.
What does this mean in a trading context?
This is easy to explain by its opposite. Let’s rewind a decade. Jon Corzine managed to blow up MF Global by focusing on the belief that European bonds (remember the Greek bond crisis?) would pay out in the end and placing that bet with extreme leverage. While the bonds eventually paid out, the margin calls buried MF Global. This is a common story. I chose it because it exemplifies how a lack of humility is the murder weapon.
The moment you employ leverage, you are worshiping at the altar of path. Corzine refused to make the appropriate sacrifices to the gods. He focused on the terminal value of the bonds. A focus so myopic, Corzine still stubbornly clings to the idea that he was right. [I once went to dinner with an option trader who worked closely with Corzine. He described him as both smart and unfazed in his path-blindness. I’d like to take issue with “smart” but he’s the one giving a fortune away, so I’ll just shut up.]
He might be rich, but if you were a stakeholder or client in MF Global, he’s a villain. Let’s not be like Jon Corzine.
Ways To Respect Path
Treat leverage with respect
The most common forms of financial leverage we employ are mortgages. The primary path risk here is needing to re-locate suddenly and potentially needing to sell at a bad time. If there are many potential forks on your horizon, the liquidity in renting can be worth it.
“Rebalance timing luck”
This is a term coined by Corey Hoffstein in his paper The Dumb (Timing) Luck of Smart Beta. First of all, this topic is central to any analysis of performance. You can have 10 different trend-following strategies with the same approximate rules but if they vary in their execution by a single day, the impact of luck can be tyrannical. Imagine one strategy was long oil the day it went negative, another strategy got out of the position one day earlier. Is the difference in performance predictive? It’s a bedeviling issue for allocators trying to parse historical returns.
If timing is not part of your alpha, then leaving it to chance can swamp the edge you worked so hard to find, capture, and market to investors. This is a recipe for disappointment for either the manager (who gets unlucky) or the investor who chose the fund from a crop of competitors based on noise.
Respecting path means smoothing the effect of rebalance timing luck. This is commonly done by dividing a single strategy into multiple strategies differing only by their rebalance schedule. The ensemble will average the luck across executions, hopefully adhering the results closer to its intended expression.
Path vs terminal value thinking
Corzine had a terminal value opinion (“if I hold these bonds to maturity I’ll get paid”). Still, any trade that is marked-to-market must still weather path. Leverage makes the trade acutely fragile with respect to path. Even if his bet was a good one at the time, the expression was negligent because it did not properly reflect his constraints.
It’s critical that the expression of a bet clings closely to its thesis. If you want to bet on the final outcome of a trade, you need to insulate the expression from path. Similarly, you can bet on path while being indifferent to the final outcome. For example, a momentum investor may devise a rule-based strategy to levitate with an inflating bubble but exit before holding the bag. These participants bet on path not terminal value. The past few years have glorified such a game of hot potato.
Whether this game of hot potato is really a game of Russian roullete depends on the expression. Many momentum strategies use stops or trailing stops to escape a trade where the trend has petered out or reversed. This expression mimics a long option position. They are creating unbounded upside and limiting their downside. This expression is banking on a dangerous assumption: liquidity. They are constructing a “soft” option presumably because they think it’s cheaper than purchasing a financial or what I call a “hard” or contractual option.
Let’s ignore realized volatility which is a first order determinant of whether the option is cheaper. The biggest problem is gap risk. Soft-option constructions assume continuity. But we know technology breaks, markets close, stocks get halted, countries invade each other, exchanges cancel trades. Pricing gap risk is impossible. That’s why derivative traders say the only hedge for an option is a similar option. Trading strategies are said to be robust to model risk if they contain offsetting exposures to the same model. If you’re short a call option on TSLA the only real hedge is to be long a different TSLA call. Reliance on the mathematical model cancels out.
Zooming in on options (feel free to skip and jump down to Investing for Path)
Some market participants focus on terminal value or the “long run” while others are focused on path. The price of options are consensus mechanisms that balance both views. I discussed this in What The Widowmaker Can Teach Us About Trade Prospecting And Fool’s Gold:
The nat gas market is very smart. The options are priced in such a way that the path is highly respected. The OTM calls are jacked, because if we see H gas trade $10, the straddle will go nuclear.
Why? Because it has to balance 2 opposing forces.
-
-
-
- It’s not clear how high the price can go in a true squeeze or shortage
- The MOST likely scenario is the price collapses back to $3 or $4.
The price has an unbounded upside, but it will most likely end up in the $3-$4 range.
Try to think of a strategy to trade that.
Good luck.
-
-
-
- Wanna trade verticals? You will find they all point right back to the $3 to $4 range.
- Upside butterflies which are the spread of call spreads (that’s not a typo…that’s what a fly is…a spread of spreads. Prove it to yourself with a pencil and paper) are zeros.
That’s not an opportunity. It’s a sucker bet.
Investors with different time horizons often trade with each other. It’s even possible they have the same long-term views but Investor A thinks X is overbought in the near-term and sells to Investor B who just wants to buy-and-hold. Investor A is hoping to buy X back cheaper. They are trying to time the market and generate trading P/L, expecting to find a more attractive entry to X later. Perhaps A is a trader more than an investor. A is obsessively conscious of near-term opportunity costs or hurdle rates. As an options trader, I am generally more focused on path than terminal value.
Let’s see how trade expression varies with your lens of terminal value vs path.
Static Expressions
A static trade expression means you put your trade on and leave it alone until some pre-defined catalyst. For options this is typically expiration. The reason you might do this is you are aware that you cannot predict the path but do not want to be shaken out of the position because you like the odds the market is offering on the terminal value of a proposition. To use natural gas, suppose the gas futures surge to $6 amidst a polar vortex but you think there is a 25% chance the price falls to $4.50 by expiration.
Suppose you can buy a vertical spread that pays 4-1 on that proposition. The bet is positive expectancy so you decide to take it. This is a discrete bet. The worst-case scenario is losing your premium. You can size the trade by feel (I’m willing to risk 1% to make 4%) or some version of Kelly sizing. Instead of trading towards a target amount of risk (whether that’s delta, vega, etc) you budget a fixed dollar amount towards it and let it ride. I refer to this type of bet as “risk-budgeting”.
When “risk-budgeting” a trade you specify a fixed bet size and you do not use leverage or pseudo-leverage (for example taking a short option position which demands margin). The point is to set-it-and-forget-it.
These types of trades were a small minority of my allocations, but they are the easiest to manage. By design, you are not getting cute with the expression, because you expect the path to your possible outcome to be hairy. This is a self-aware strategy for respecting path.
Dynamic Expressions
Most of my trades were actively managed. Running a large options portfolio means lots of churn as you whack-a-mole opportunities. You find more attractive positions to warehouse than what’s currently on the books, or perhaps you are adding to get to a more full-size position.
The key is most of the focus is on path not terminal value. Sometimes I’m buying vol because I have a view on volatility, but often I’m buying vol if I think there are going to be more vol buyers. The first kind of buying is a hybrid of path and terminal value thinking, but the second type of vol buying has a momentum mindset. My view on realized vol takes a backseat to my view on flows if I think the option demand will exceed supply at current levels of implied volatility.
Other dynamic trade expressions:
-
- Implied sentiment
Another path-aware expression is to bet on the expectations embedded in prices. I might load up on oil calls not because I think oil is going to $200, but because I think the awareness that such a price is possible can emerge due to some catalyst (“saber-rattling”). I’m thinking in terms of path not terminal value when my thesis is “sentiment can go from apathy to fear”. I’m betting on a change in the Overton Window. The change in sentiment can increase call option implied vols and even the futures. But the option trade expression is a purer play than the futures.
[The number of ways an oil future can rise is greater than the number of drivers to push oil call skew higher, so the call options isolate the thesis better by being directly levered to it. Agustin Lebron’s 3rd Law Of Trading: Only take the risks you are paid to take.]
- Owning the wing
Tail options are on average “expensive” in actuarial terms. But there are several reasons why I do not short them.
- “Average” is hiding a lot of detail. The excess premium in those options can be proportionally small to what those options can be worth conditional on stressed states of the world. Buying them when they are relatively cheap to their own elevated premiums can be worthwhile, especially if those options put you in the driver’s seat when the world starts melting down. If you are the only one with bullets in a warzone, there’s a good chance you have them because the terminal-value-Jon-Corzine crowd underestimated path. Then you can sell the options “closing” at truly outlandish prices. I want the tails because I don’t want to be running a trading business with a prime broker’s trapdoor beneath me.
- I’m not smart enough to know when to sell tail options opening. I buy them when they are relatively cheap (which usually still means expensive to Corzine brains) and I sell them closing when they go nuclear. Like when you throw some insane offer out there and it gets taken. As a rule you don’t want to sell wings to someone who spent more than a few moments thinking about it or used a spreadsheet or model or calculator or star chart. You sell them to people who are forced to buy them. When Goldman blows their customer out they don’t haggle.
In practice, ratio put spreads look attractive to terminal value people who like to “buy the one and sell the two” because their breakeven is so “far” out-of-the-money and they get to win on medium drawdowns. I often like to sell the 1 and buy the 2 because conditional on the 1×2 “getting there”, the 2 are going to be untouchable.
[The buyer of the one in a 1×2 is happiest in the grinding trend scenario where strike vols underperform the skew.]
- In The “No Easy Trade” Principle I explain how implied market parameters do not vary as widely as realized parameters because markets are discounting machines.
Markets bet on mean reversion. Vols often underreact when they are rising (or falling) as the regime changes. These turns can be great path trades. They are momentum opportunities to lift or hit slower participants who are anchored to the prior regime. These opportunities are very profitable since you are not only putting the bet on the right way, but you are able to get liquidity from stale actors. (The trouble with many opportunities is getting liquidity — if you know something is going up but everyone else does too, your signal is valid but insufficiently differentiated. Turning every measly 5 lot offer into a new bid makes the market more efficient without extracting a reward for it. In fact, if you do that, you don’t understand expectancy or the principle of maximization. Your job isn’t to correct incorrect markets. It’s to make money. The overlap is imperfect.) The challenge is you somehow need to not be anchored yourself .
- Humility is recognizing that the craziest event has yet to happen. Market shocks are a feature. They look different every time because we prepare for the last war. The instruments that measure our vitals become the targets themselves. Tail options provide volatility convexity, or exposure to “vol of vol”. You don’t need to know the nature of the next shock to know that you will have wanted vol convexity. See Finding Vol Convexity.
Combining Expressions
I’ll mention this for completeness but it’s a topic I should probably do a video for. It’s not complicated but it’s a bit technical for a post like this. When running an options book, it’s possible to treat some of the positions dynamically and some of them statically. In practice, I “remove” line items that have well-defined risks from of my position at the most recent mark-to-market value so that I do not incorporate their Greeks into my book. I don’t hedge it with the rest of the pile.
For example, if I notice an out-of-the-money put spread on my books, instead of dynamically managing a position that was short a tail, I’d put the spread in another account and sell the corresponding delta hedge associated with it. Going forward it would not generate any Greeks in my main risk view so there’s no need to hedge (remember hedging is a cost). The risk is sequestered to the premium. Let’s say it’s $75,000 worth of put spreads. The expectancy of the spread is presumably zero, so it’s like having a simple over/under bet on the books. If expiration goes my way I get to make a multiple of that, but I know the worst (and most likely) case is losing $75k which given the size of the book is noise. If my capital swamps the risk, there’s no point in hedging it especially since it’s short a tail that’s sensitive to vol of vol.
Investing for path
VCs
Venture capital is a strategy that is robust to path. The fact that the portfolio marks are fairy dust helps, but in this context is not important. Why is venture a strategy that exploits divergence in the tails?
Because from its construction, it admits it doesn’t know much. If you believe you are sampling from start-ups that have a power-law distribution (admittedly a big “if”), then the correct strategy is indeed to “spray and pray”.
Byrne Hobart piggybacks Jerry Neumann in his explanation:
One of my favorite blog posts on venture returns is Jerry Neumann’s power laws in venture. His key point is that if venture returns follow a power-law distribution, average returns rise indefinitely as you get a bigger sample set. There is no well-defined mean! If you measure adult height, you quickly converge on 5’9” for American men and 5’4” for American women. You will find outliers, but they’re equally common at both ends of the distribution. But if you measure startup investing returns, you’ll keep getting tripped up: flop, failure, failure, flop, Google, fad, fraud, freaky scandal, Facebook…
Does this imply that the ideal strategy for venture is to invest in as many companies as possible? If you’re sampling from a power-law distribution, that’s what you should do.
Lux Capital partner Josh Wolfe’s approach epitomizes the spirit of searching for gold in the tails. On Invest Like The Best, he explained his investing beliefs:
- Confident that curiosity, following leads, and relentlessness will lead you to the next idea.
- Confident you won’t know when or how you happen upon the idea.
- Confident that the idea lies in the edges of companies that are doing innovative things, often from first principles or science, and very few people are looking there.
These principles propagate from a commitment to benefitting from optionality and positive convexity of non-linear relationships.
The key line follows:
When analyzing how they found deals it only made linear, narrative sense after the fact.
This is reinforced in On Contrarianism, where I quote Wolfe as well as Marc Andreesen and trader Agustin Lebron on why the best investments start out controversial. The gist is that an idea must be so radical and far-fetched that it doesn’t get bid up while also being possible. The intersection of great ideas after-the-fact that sound dumb before-the-fact is nearly invisible. Most ideas people think are dumb, are indeed, dumb. Venture understands this and systematically wraps a sound process around a low hit rate.
“Gorilla” Investing
Gorilla investing is another strategy designed to look like a long option. The gist of it is to invest an equal amount in a list of candidates that are competing for a giant market. As the winners start pulling away, you shed the losers and reallocate the proceeds back into the winners.
Since it rebalances away from losers into winners, it explicitly bets against mean reversion. It’s a divergent strategy that growth investors employ in winner-take-all sectors.
The strategy requires extensive judgment, but I highlight it as another example of an investing algorithm with roots in epistemic humility. If you want to learn more about this strategy see the notes for Gorilla Game or pick up the book.
Conclusion
Like venture or Rohit’s advice on recruiting, gorilla investing casts a wide net from a sufficiently narrowed field and lets attrition decide where to allocate more. In Where Does Convexity Come From? I explain that that the essence of convexity is a non-linear p/l resulting from a change in your position size in the same direction as the return of your position. Your exposure to a winning trade grows the more it wins.
Byrne writes:
Since venture success is defined by dealflow, i.e. by whether or not you have a chance to invest in the hottest companies, the main function of the Series A investment is to get a chance to invest in Series B and Series C and so on. Arguably, the better the fund, the more of its real value today consists of pro-rata rights rather than the investments themselves.
That’s a general case of positive convexity: the better the situation, the higher your exposure.
This is the essence of capturing the upside when our signals struggle to parse winners from an exclusive field. If we cannot predict what will happen in the tails, the next best thing is the ability to increase our exposure to momentum when it’s going our way. This begins with humility and funneling wider than our instincts suggest. From that point, we let actual performance provide us with incremental information on what works and what doesn’t.
Contrast this with a model that takes itself more seriously than tail correlations warrant. The model is filtering prematurely. We don’t look for tomorrow’s star athletes amongst the best 8-year-olds because we know puberty is a reshuffling machine.
Keep in mind:
- Correlations break down or invert in the extreme
- Make your selections robust to path or possibly taking advantage of it.
- Systematize finding gold in diversity. There’s a decent chance others won’t be looking there.
Happy prospecting!
If you use options to hedge or invest, check out the moontower.ai option trading analytics platform

















 Unlock One Another: The Right Compliment At The Right Time (
Unlock One Another: The Right Compliment At The Right Time (








